Promedio de descarga/visualización de los códigos de SQL Server
Listado de los códigos con más promedio de visualizaciones realizadas por día desde su publicación en la web.
Aprovechando que para unas cosas de la escuela tuve que instalar SQL Server y SQL Server Management Studio (ya que por voluntad propia no lo haría jamás) decidí conectar PHP con SQL Server y hacer un CRUD, es decir, create, read, update y delete de una base de datos de SQL Server.
Tabla de contenido:
1 Preparar entorno
2 Esquema de la tabla
3 DSN de PDO
4 Leer datos
4.1 Con arreglo
5 Con cursor
6 Insertar datos
7 Actualizar datos
8 Obtener un dato
9 Eliminar datos
10 Poniendo todo junto
10.1 Listar
11 Insertar
11.1 Editar
12 Eliminar
13 Conclusión
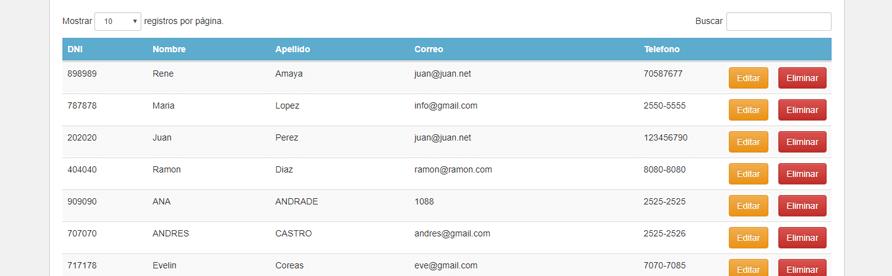
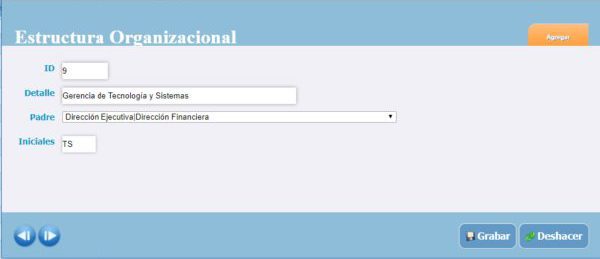
Al desarrollar aplicaciones de Bases de Datos, es necesario programar los formularios necesarios para darle mantenimiento a las diferentes tablas que guardan la información del sistema. Cuando se tienen varias decenas o cientos de tablas, crear y mantener igual cantidad de formularios se convierte en una tarea de programación y mantenimiento bastante complicada....
Este documento pretende ser una guía de las diferencias más importantes entre las bases de datos Access, MSDE y SQL Server, todas de Microsoft.
Para poner a punto SQL Server es necesario ajustar la configuración, opciones, y valores de setup basadas en las observaciones de las características de trabajo del servidor. Típicamente estas observaciones se hacen durante el periodo de trabajo mas critico de servidor para perfeccionar las cargas de trabajo más pesadas. Las recomendaciones de afinación siguientes son aquéllas que generalmente tienen el mayor impacto en el trabajo de Servidor. Sin embargo, la aplicación de estas recomendaciones puede producir resultados diferentes que dependen del ambiente particular del Servidor.
En este artículo se explica como optimizar SQL server.
Desarrollo de aplicaciones conducida por bases de datos

Nos adentramos en el desarrollo de aplicaciones y cuando escribimos código, independientemente del lenguaje de programación que se utilice, la primera opción, la mas “plana”, aunque la que genera mas texto, es la del “código rígido”.
en Microsoft SQL Server se han utilizado mapas de bits internamente para acelerar la ejecución de consultas desde la versión 7.0. Con la introducción de nuevos operadores en SQL Server 2000, se pueden aplicar más técnicas de filtrado de mapas de bits para obtener una rapidez incluso mayor en la ejecución de consultas con paquetes de datos de más volumen.
Con el SQL Server 2005 Management Studio Express puedes crear copias de seguridad de las bases de datos que tengas definidas en el servidor de SQL Server.
Esa copia de seguridad la puedes volver a restaurar en ese mismo equipo o en otro diferente.
Aquí te explico de forma sencilla cómo realizar una copia de seguridad de una base de datos y después cómo usar una base de datos a partir de una copia. En este ejemplo también te explico cómo restaurar una base de datos que hayas copiado, pero con otro nombre, con idea de que puedas comprobar si esa copia está bien... ya que no tiene mucho sentido hacer una copia de seguridad si después no nos sirve de nada...
Articulo en el que se detalla como cambiar la ubicación de bases de datos SQL Server en el servidor. En formato HTML.
Pequeña descripción de que es y como se evita la inyección SQL usando como ejemplo una base de datos con SQL Server y una página en ASP.
Hoy en día la utilización de bases de datos es algo fundamental en cualquier aplicación, y por lógica su uso se ha extendido en las empresas, tanto offline como online. Las aplicaciones web y de escritorio las usan para escribir, modificar y recuperar información de forma rápida.
Al comenzar a trabajar con bases de datos nos enfrentaremos a un concepto nuevo, el cual se conoce como servidor de base de datos.
En el artículo de hoy exploraremos el concepto, sus funciones, características y cuáles son los mejores servidores de bases de datos para usar en tus apps.
Índice de Contenidos:
1 ¿Qué es un Servidor de Base de Datos?
2 Funciones de un Servidor de Base de Datos
3 Usos populares de servidores de bases de datos
4 Ejemplos de Servidor de Bases de Datos
4.1 MySQL server
4.2 PostgreSQL server
4.3 Microsoft SQL Server
4.4 MongoDB server
5 Arquitectura de hardware y red para tu servidor de base de datos
6 ¿Qué servidor de base de datos debo elegir?

El tiempo de recuperación de bases de datos durante el inicio de SQL Server o la carga de los registros de transacciones puede llegar a ser bastante largo y durante ese tiempo no es fácil determinar el estado de la recuperación. En este artículo se describen los pasos necesarios para solucionar este problema.
Aprende paso a paso a instalar y configurar SQL Server 2012 en Windows 7.
En Microsoft SQL Server se han utilizado mapas de bits internamente para acelerar la ejecución de consultas desde la versión 7.0. Con la introducción de nuevos operadores en SQL Server 2000, se pueden aplicar más técnicas de filtrado de mapas de bits para obtener una rapidez incluso mayor en la ejecución de consultas con paquetes de datos de más volumen.
Si necesita que una tabla temporal persista en procedimientos almacenados no anidados y desea eliminar dicha tabla cuando ya no la necesite, puede crear dinámicamente tablas permanentes en el código. Este artículo muestra un ejemplo de este procedimiento.
Se pueden agrupar instrucciones SQL y el lenguaje de control de flujo en un procedimiento almacenado para mejorar el funcionamiento de SQL Server. Además, puede utilizar un grupo de procedimientos predefinidos, llamados procedimientos almacenados del sistema, para realizar tareas administrativas y actualizar las tablas del sistema.
Cuando se mueven bases de datos a un nuevo servidor, es posible que los usuarios no puedan iniciar sesión en él. En su lugar, reciben el siguiente mensaje de error: Msj 18456, Nivel 16, Estado 1, Error de inicio de sesión del usuario '%ls'.
Es necesario transferir los inicios de sesión y las contraseñas al nuevo servidor. En este artículo se describe cómo transferir los inicios de sesión y las contraseñas a un nuevo servidor.
El primero es una serie de artículos por Michael Rys en los cuales detalla las nuevas capacidades más importantes de la cláusula FOR XML del lado del servidor en la nueva versión de SQL Server. Estas le permiten mejorar el soporte XML en sus aplicaciones y escribir datos relacionales a agregados XML fáciles de mantener.
La duplicación es una tecnología importante y eficaz para distribuir datos y procedimientos almacenados por toda una empresa. La tecnología de duplicación de Microsoft SQL Server permite realizar copias de los datos, mover dichas copias a distintas ubicaciones y sincronizar los datos automáticamente con el fin de que todas las copias tengan los mismos valores en los datos. La duplicación puede implementarse entre bases de datos del mismo servidor o entre distintos servidores conectados a través de LAN, WAN o Internet. Mediante la combinación de SQL Server y Microsoft Proxy Server, es posible duplicar datos sobre Internet sin que ello ponga en peligro la seguridad de ninguna base de datos. Los pasos implicados en la implementación de la duplicación a través de Internet incluyen: la configuración de la topología de la red, el conocimiento de la metodología de seguridad, la configuración de Proxy Server y la configuración de SQL Server versión 7.0 para la duplicación.
Aprende (o repasa) cómo funcionan las consultas J0IN y sus variantes en SQL.
Los conceptos que vamos a revisar hoy, aplican en general para las bases de datos relacionales.
Sin embargo, por esta vez, usaremos de forma específica SQL Server.
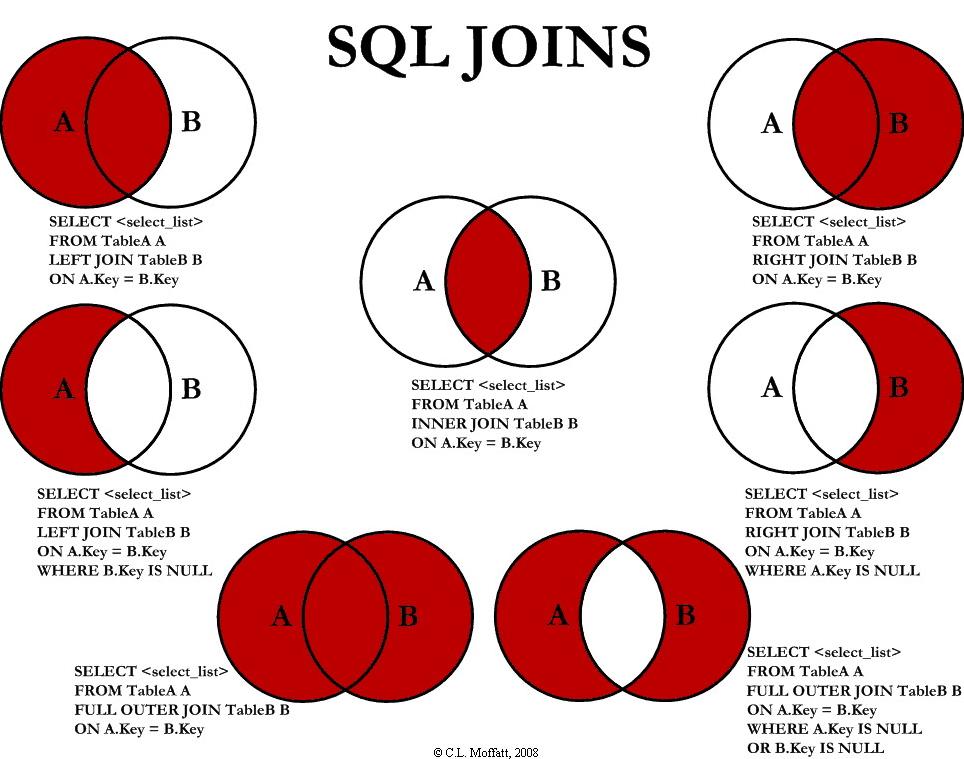
De manera recurrente aparece una pregunta en los grupos de noticias y en los foros sobre el tamaño del fichero de transacciones de una base de datos del SQL Server.
Realmente este error no es un problema del SQL Server. Es el comportamiento normal del servidor cuando no tenemos en cuenta que en toda base de datos hay que realizar una serie de tareas de mantenimiento para que todo funcione correctamente. Lo que nos está indicando es que el fichero de log no puede crecer más, bien sea porque le hemos limitado el tamaño o porque hemos llenado todo el disco, y si el servidor no puede escribir en el fichero de log no puede continuar trabajando. Pero vamos a ver un poco como funciona el almacenamiento de datos en el SQL Server y que es eso del fichero de transacciones (o de log) para entender como podemos solucionar este error, y lo que es más importante, como evitarlo.
Los procedimientos almacenados de SQL Server son una gran herramienta para poder hacer parte de nuestro trabajo de acceso a datos dentro del propio servidor.
Pero cuando empezamos a crear procedimientos almacenados cada vez más y más complicados llega un momento en el que nos encontramos con la necesidad de que nuestro procedimiento reciba un número indeterminado de parámetros.
Cuando esto me ocurrió a mi recuerdo que me puse a buscar en los BOL como podía pasar un Array a mi procedimiento, pero me encontré con la imposibilidad de trabajar con Arrays en TSQL.
Así que buscando un poco más encontré un par de métodos para hacer el trabajo "a mano" y eso es lo que vamos a comentar aquí.
¿Cómo decide el optimizador de consultas cuál es la mejor manera de recuperar los datos de una consulta SQL? ¿Cómo se pueden accesar, crear o mantener las estadísticas de consulta del SQL Server 2000? ¿Para qué más pueden servir? Estas y otras cuestiones son respondidas en este artículo de Lubor Kollar.
En este artículo se introduce a los programadores de Microsoft SQL Server en las características internacionales de Microsoft SQL Server 2005. Entre los temas tratados se incluyen una explicación de Unicode, la compatibilidad agregada para caracteres adicionales en SQL Server 2005, los cambios en la intercalación en diferentes versiones de SQL Server, los cambios en tipos de datos, el rendimiento, las actualizaciones en proveedores de datos y las nuevas características internacionales de compatibilidad en SQL Server 2005 Analysis Services e Integration Services.
En este artículo se describe qué datos se recopilan y dónde se almacenan. También se describen los comandos que crean, actualizan y eliminan estadísticas sobre los índices y los datos de columna almacenados en la base de datos de Microsoft SQL Server 2000.
A menudo necesitamos obtener información de dos servidores o más explicitamente de dos instancias SQL desde la misma consulta.
Esto se puede realizar de mútiples formas, aunque una de las más simples es utilizar servidores vinculados. Para esto vamos a realizar un laboratorio con dos instancias diferentes, desde el Management Studio y también desde TSQL.
Articulo que te detalla la forma de agregar una imagen en la base de datos.
Esta pregunta debe ser una de las que mas se me hacen y las que respondo en los diferentes foros o News, por tal motivo me he concentrado en tratar de escribir este artículo que tratara de explicar como usar las Fechas en Sql Server y que cosas debemos tomar en consideración.
Antes de empezar voy a tratar de explicar que son las Fechas para SqlServer: Este mismo tiene básicamente dos tipos de datos donde se pueden almacenar fechas propiamente dichas: Datetime y SmallDateTime, en este cuadro veremos las diferencias entre estos dos tipos de Datos.
Los clientes de SQL Server 2000 se conectan a SQL Server con una pila de API, bibliotecas de objetos y protocolos. Ken Henderson nos mostrará todos estos elementos y explicará su modo de funcionamiento e interacción.
La solución y la reparación de consultas erróneas, así como la resolución de problemas de rendimiento pueden implicar horas (o días) de investigación y pruebas de errores. A veces podemos reducir rápidamente ese tiempo identificando patrones de diseño comunes que son indicativos de un TSQL de bajo rendimiento.
El desarrollo del reconocimiento de estos patrones para estas zonas de ojos súper críticos, de detectar errores puede permitirnos enfocarnos inmediatamente en lo que es más probable que sea el problema. Mientras que contrariamente el ajuste del rendimiento a menudo puede estar compuesto por horas de recopilación de eventos extendidos, seguimientos, planes de ejecución y estadísticas, y la posibilidad de ser capaz de identificar posibles escollos rápidamente puede provocar un cortocircuito en todo ese trabajo.
Si bien debemos realizar nuestra debida diligencia y demostrar que cualquier cambio que hagamos sea óptimo, ¡saber por dónde empezar puede ahorrar mucho tiempo!

Los procedimientos almacenados de SQL Server son una gran herramienta para poder hacer parte de nuestro trabajo de acceso a datos dentro del propio servidor.
Pero cuando empezamos a crear procedimientos almacenados cada vez más y más complicados llega un momento en el que nos encontramos con la necesidad de que nuestro procedimiento reciba un número indeterminado de parámetros.
Cuando esto me ocurrió a mi recuerdo que me puse a buscar en los BOL como podía pasar un Array a mi procedimiento, pero me encontré con la imposibilidad de trabajar con Arrays en TSQL.
Así que buscando un poco más encontré un par de métodos para hacer el trabajo "a mano" y eso es lo que vamos a comentar aquí.

 Conectar PHP y SQL Server usando PDO – CRUD de ejemplo
Conectar PHP y SQL Server usando PDO – CRUD de ejemplo
