*****************************************************************************************************************
Ejercicio:Aula_28_token_sep_24.py
*********************************
Vamos a avanzar en el Aula 28, e iniciar, el tratamiento de textos en la Inteligencia Artificial.
Empezaremos con algo muy básico, ¿Qué es la tokenización?.
--------------------------------------------------------
-¿Qué es la tokenización?
Dividir el texto: La tokenización consiste en dividir un texto en partes más pequeñas llamadas tokens. Estos tokens pueden ser palabras, frases o incluso caracteres, dependiendo de cómo quieras analizarlos.
Ejemplo: Si tienes la frase "El perro ladra", la tokenización a nivel de palabras dividiría el texto en los siguientes tokens:
"El"
"perro"
"ladra"
Importancia:
-----------
Facilita el análisis: Al descomponer el texto, es más fácil realizar análisis, como contar palabras, buscar patrones o entender el significado.
Prepara para modelos:
Muchos modelos de IA trabajan con números, no con texto. La tokenización es un primer paso para convertir texto en un formato que los modelos puedan entender.
Tipos de tokenización:
---------------------
Por palabra: Divide el texto en palabras.
Por frase: Divide el texto en oraciones o frases.
Por carácter: Divide el texto en caracteres individuales.
Como ya digimos, la tokenización es el proceso de separar el texto en unidades más pequeñas (tokens) para que puedan ser analizadas y procesadas por algoritmos de IA. Es un paso esencial para entender y trabajar con el lenguaje en aplicaciones de inteligencia artificial.
*****************************************************************************************
Como se almacenaría, por ejemplo, en una matriz del tipo Tensor.
---------------------------------------------------------------
Definición: Un tensor es una estructura de datos que puede ser vista como una generalización de matrices y vectores.
Un escalar es un tensor de orden 0 (por ejemplo, un solo número).
Un vector es un tensor de orden 1 (una lista de números).
Una matriz es un tensor de orden 2 (una tabla de números).
Un tensor de orden superior puede tener más de dos dimensiones.
Representación: En matemáticas, los tensores se utilizan para representar datos de múltiples dimensiones. Por ejemplo, una imagen puede ser representada como un tensor de 3 dimensiones (alto, ancho, canales de color).
¿Cómo se utilizan los tensores en IA y procesamiento de texto?
Representación de texto:
Después de la tokenización, los tokens (palabras o frases) deben convertirse en números para que los algoritmos de IA puedan procesarlos. Esto se hace a menudo usando técnicas de embeddings (representaciones vectoriales de palabras).
Cada token se convierte en un vector (tensor de orden 1). Por ejemplo, la palabra "perro" podría representarse como un vector de características [0.5, 0.1, 0.9, ...].
Tensores en redes neuronales:
Los tensores son fundamentales en el entrenamiento de redes neuronales, donde los datos se alimentan a través de capas de la red. Cada capa procesa los tensores de entrada y produce tensores de salida.
Por ejemplo, en un modelo de procesamiento del lenguaje natural (como Transformers), el texto tokenizado se convierte en tensores, que luego son procesados en múltiples capas para generar resultados (como predicciones de texto).
Operaciones con tensores:
Se realizan varias operaciones matemáticas sobre tensores, como la suma, la multiplicación y la transformación, para aprender patrones en los datos. Esto se hace utilizando bibliotecas de programación como TensorFlow o PyTorch, que son especialmente diseñadas para manejar tensores y operaciones sobre ellos.
Batching:
En el entrenamiento de modelos, es común agrupar múltiples ejemplos en un batch (lote). Esto se hace representando varios textos como un tensor de 2 dimensiones (batch_size, longitud del texto), donde batch_size es el número de ejemplos en el lote y longitud del texto es el número máximo de tokens por ejemplo.
Diriamos, como conclusion.
------------------------
Los tensores son estructuras de datos esenciales en IA y procesamiento de texto. Se utilizan para representar texto, imágenes y otros tipos de datos en múltiples dimensiones. En el contexto del procesamiento de texto, los tensores permiten a los modelos de IA realizar cálculos complejos y aprender patrones a partir de datos tokenizados. Su uso se ha vuelto fundamental en la mayoría de las aplicaciones modernas de inteligencia artificial y aprendizaje profundo.
***************************************************************************************
EXPLICACCION DE NUESTRO EJERCICIO.
****************************************************************************************
Vamos a desglosar el ejercicio proporcionado paso a paso para entender cómo funciona y qué hace cada parte del código.
1. Importación de bibliotecas
****************************
import nltk
from nltk.tokenize import word_tokenize
import nltk: Importa la biblioteca Natural Language Toolkit (NLTK), que es una biblioteca popular en Python para el procesamiento del lenguaje natural.
from nltk.tokenize import word_tokenize: Importa la función word_tokenize, que se utiliza para dividir un texto en palabras (tokens).
2. Definición de la función
**************************
def tokenizar_con_matriz(frase):
Aquí se define una función llamada tokenizar_con_matriz, que acepta una cadena de texto (frase) como argumento.
3. Docstring
***********
"""Tokeniza una frase y crea una matriz 2D con los tokens y sus índices.
Args:
frase: La frase a tokenizar.
Returns:
Una lista de listas donde cada sublista contiene el token y su índice.
"""
Este bloque de texto es un comentario (docstring) que describe lo que hace la función, los argumentos que recibe y lo que devuelve. Es útil para que otros programadores (o tú mismo en el futuro) entiendan el propósito de la función.
4. Tokenización
**************
tokens = word_tokenize(frase)
word_tokenize(frase): Esta función toma la frase y la divide en una lista de tokens (palabras y puntuaciones). Por ejemplo, si la entrada es "El mar, amplio y profundo", tokens podría ser ['El', 'mar', ',', 'amplio', 'y', 'profundo'].
5. Creación de la matriz de tokens
*********************************
matriz_tokens = [[token, str(indice)] for indice, token in enumerate(tokens, start=1)]
enumerate(tokens, start=1): Esta función permite iterar sobre tokens, proporcionando tanto el índice (número de posición) como el valor del token. La opción start=1 significa que los índices comenzarán desde 1 en lugar de 0.
Lista de listas: Se crea una lista llamada matriz_tokens, donde cada sublista contiene un token y su índice correspondiente. Por ejemplo, si tokens es ['El', 'mar', ',', 'amplio', 'y', 'profundo'], matriz_tokens sería:
css
[['El', '1'],
['mar', '2'],
[',', '3'],
['amplio', '4'],
['y', '5'],
['profundo', '6']]
6. Solicitar entrada al usuario
*******************************
# Solicitar al usuario que introduzca la frase
frase = input("Introduce una frase: ")
Aquí se le pide al usuario que introduzca una frase a través de la consola. Lo que escriba el usuario se almacenará en la variable frase.
7. Llamada a la función y almacenamiento del resultado
******************************************************
matriz = tokenizar_con_matriz(frase)
Se llama a la función tokenizar_con_matriz, pasando la frase que el usuario introdujo como argumento. El resultado (la matriz de tokens) se guarda en la variable matriz.
8. Impresión de la matriz
************************
# Imprimir la matriz completa
for fila in matriz:
print(fila)
Este bucle for recorre cada sublista (fila) en matriz y las imprime. Cada fila contendrá un token y su índice, mostrando el resultado de la tokenización de forma estructurada.
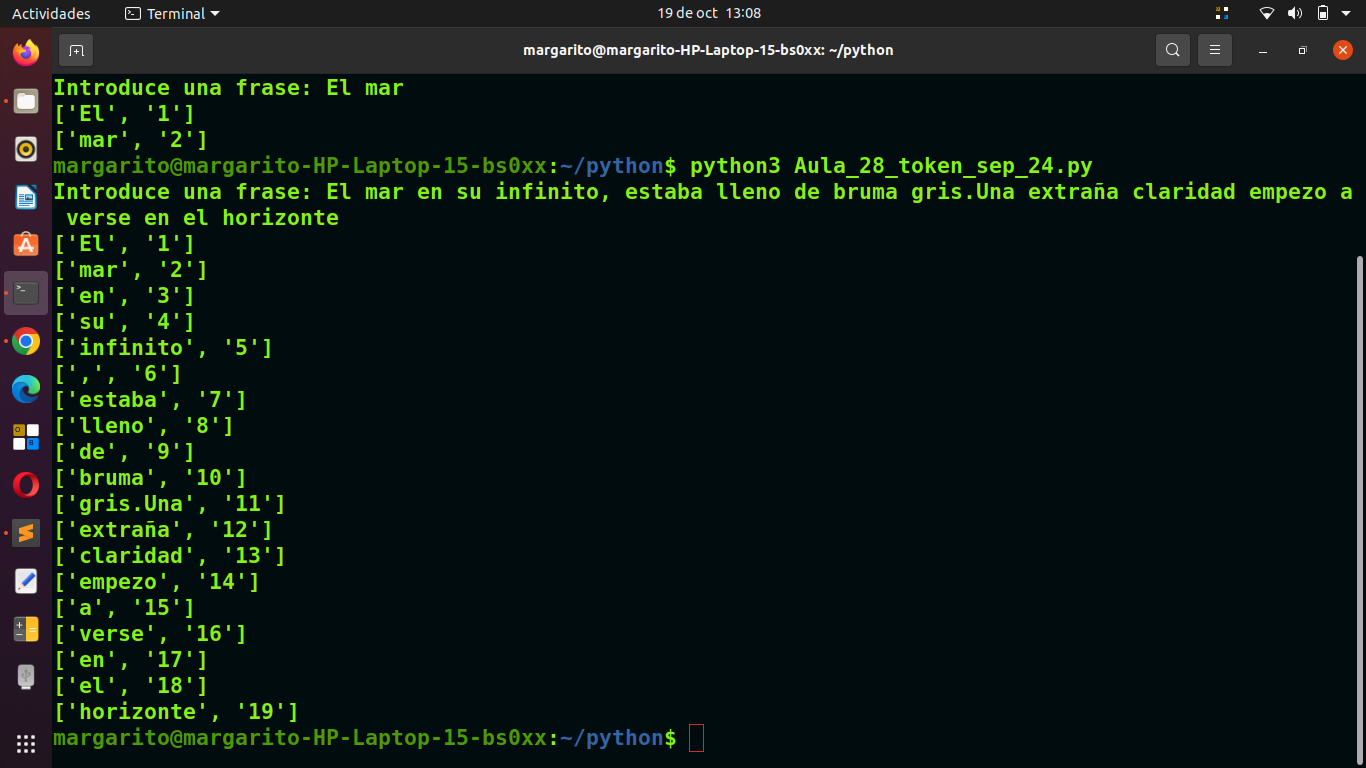
Ejemplo de uso
Si el usuario ingresa la frase:
El mar, amplio y profundo
La salida sería:
css
['El', '1']
['mar', '2']
[',', '3']
['amplio', '4']
['y', '5']
['profundo', '6']
Podemos decir, queridos alumnos, como esumen que:
-------------------------------------------------
Este programa tokeniza una frase ingresada por el usuario, crea una estructura de datos en forma de matriz que muestra cada token y su índice correspondiente, y luego imprime esa matriz. Este ejercicio que os propuse, es un ejemplo básico pero efectivo de cómo manipular texto en Python utilizando NLTK.
*************************************************************************************************
Este ejercicio fue ralizado bajo Linux, en sistema operativo Ubuntu,
Editado con sublime text.