Red-CNN Detección de bordes
Python
Publicado el 19 de Febrero del 2024 por Hilario (144 códigos)
431 visualizaciones desde el 19 de Febrero del 2024

Los kernels Sobel son filtros utilizados comúnmente en procesamiento de imágenes para realizar operaciones de convolución, especialmente en el contexto de detección de bordes. Estos filtros están diseñados para resaltar cambios rápidos en la intensidad de los píxeles en una imagen, lo que generalmente indica la presencia de bordes.
El operador Sobel consiste en dos kernels, uno para la detección de cambios horizontales y otro para cambios verticales. Estos kernels son matrices pequeñas que se aplican a la imagen mediante la operación de convolución. Los kernels Sobel comúnmente utilizados son los siguientes:
Kernel Sobel para detección de bordes horizontales (kernel_sobel_x):
[ -1, 0, 1]
[ -2, 0, 2]
[ -1, 0, 1]
Kernel Sobel para detección de bordes verticales (kernel_sobel_y):
[ 1, 2, 1]
[ 0, 0, 0]
[-1, -2, -1]
La operación de convolución implica deslizar estos kernels sobre la imagen original, multiplicando los valores de los píxeles en la región correspondiente del kernel y sumándolos para obtener un nuevo valor en la posición central. Este proceso se repite para cada píxel en la imagen, generando así dos nuevas imágenes filtradas: una resaltando cambios horizontales y otra resaltando cambios verticales.
La magnitud de los bordes se calcula combinando las respuestas horizontales y verticales mediante una fórmula de magnitud Euclidiana.
Este resultado proporciona una representación de la intensidad de los bordes en la imagen original, lo cual es útil para tareas como detección de contornos. En el código que compartiste anteriormente, estos kernels Sobel se utilizan para realizar la detección de bordes en la imagen cargada.
Este programa en Python: python3 Aula_28_bordes_CNN.py, realiza la detección de bordes en una imagen utilizando el operador Sobel. Aquí tienes una explicación paso a paso:
Cargar la imagen:
Utiliza la biblioteca OpenCV (cv2) para cargar una imagen desde la ruta "/home/margarito/python/tulipanes.jpeg".
Verifica si la carga de la imagen fue exitosa.
Convertir la imagen a formato RGB:
Utiliza la función cv2.cvtColor para convertir la imagen cargada (en formato BGR) a formato RGB.
Muestra la imagen original utilizando la biblioteca matplotlib.
Definir los kernels Sobel:
Define dos kernels Sobel, uno para la detección de bordes horizontales (kernel_sobel_x) y otro para la detección de bordes verticales (kernel_sobel_y).
Aplicar los filtros Sobel:
Utiliza la función cv2.filter2D para aplicar los filtros Sobel a la imagen original, obteniendo dos imágenes resultantes (imagen_bordes_x e imagen_bordes_y), que representan los bordes horizontales y verticales, respectivamente.
Calcular la magnitud de los bordes:
Calcula la magnitud de los bordes combinando las imágenes resultantes de los filtros Sobel mediante la fórmula de la magnitud Euclidiana.
Verificar si hay datos válidos en la matriz antes de normalizar:
Antes de normalizar la magnitud de los bordes, verifica si hay datos válidos en la matriz utilizando np.any.
Convertir a tipo de datos float32 antes de normalizar:
Convierte la matriz de magnitud de bordes a tipo de datos float32. Esto es necesario para evitar problemas de normalización con tipos de datos no compatibles.
Normalizar la imagen:
Utiliza el método de normalización para escalar los valores de la magnitud de los bordes al rango [0, 1]. Esto es importante para visualizar correctamente la imagen de bordes.
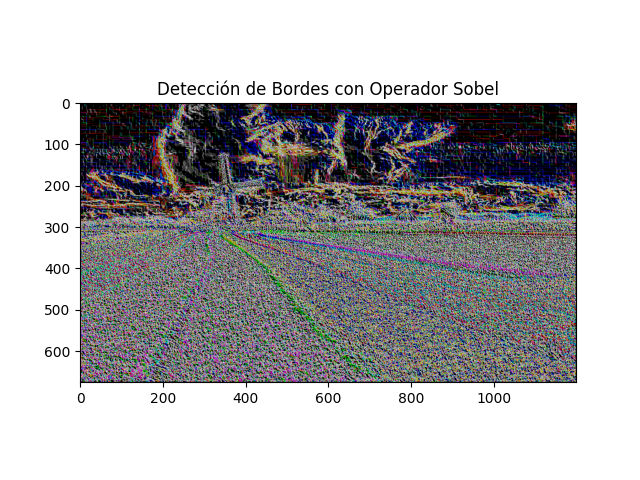
Mostrar la imagen con bordes:
Utiliza plt.imshow para mostrar la imagen resultante de la detección de bordes en escala de grises.
Muestra un título indicando que se ha aplicado el operador Sobel para la detección de bordes.
Manejar casos donde la matriz de magnitud de bordes está vacía:
Si la matriz de magnitud de bordes está vacía (todos los elementos son cero), imprime un mensaje indicando que la matriz está vacía o no contiene datos válidos.
En resumen, este programa carga una imagen, aplica el operador Sobel para detectar bordes y muestra la imagen resultante de la detección de bordes. Además, maneja casos donde la matriz de magnitud de bordes no contiene datos válidos.