Mostrar los tags: es
Mostrando del 21 al 30 de 734 coincidencias
Se ha buscado por el tag: es
Hilario Iglesias Martínez.
*****************************************
Ejercicio:
CuadernoEstocas-Aula-48-15-SEP-RV-2.py
-----------------------------------------
Ejecución:python3 CuadernoEstocas-Aula-48-15-SEP-RV-2.py
******************************************
Se prueba con los valores con pareamétros mínimos,
con el fin de apreciar su funcionamiento:
learning_rate = 0.01
n_iterations = 4
np.random.seed(0)
X = 2 * np.random.rand(4, 1)
y = 4 + 3 * X + np.random.randn(4, 1)
-------------------------------------------
Creado bajo plataforma Linux.
Ubuntu 20.04.6 LTS
Editado con Sublime Text.
Ejecutado bajo consola linux:
python3 CuadernoEstocas-Aula-48-15-SEP-RV-2.py
"""Hilario Iglesias Marínez
*******************************************************************
Ejercicio:
Estocástico_Aula_F-890.py
Ejecucion bajo Consola Linux:
python3 Estocástico_Aula_F-890.py
******************************************************************
Diferencias.
El descenso de gradiente es un algoritmo de optimización utilizado comúnmente en el aprendizaje automático y la optimización de funciones. Hay dos variantes principales del descenso de gradiente: el descenso de gradiente tipo Batch (también conocido como descenso de gradiente por lotes) y el descenso de gradiente estocástico. Estas dos variantes difieren en la forma en que utilizan los datos de entrenamiento para actualizar los parámetros del modelo en cada iteración.
Descenso de Gradiente Tipo Batch:
En el descenso de gradiente tipo Batch, se utiliza el conjunto completo de datos de entrenamiento en cada iteración del algoritmo para calcular el gradiente de la función de costo con respecto a los parámetros del modelo.
El gradiente se calcula tomando el promedio de los gradientes de todas las muestras de entrenamiento.
Luego, se actualizan los parámetros del modelo utilizando este gradiente promedio.
El proceso se repite hasta que se alcanza una convergencia satisfactoria o se ejecuta un número predefinido de iteraciones.
Descenso de Gradiente Estocástico (SGD):
En el descenso de gradiente estocástico, en cada iteración se selecciona una sola muestra de entrenamiento al azar y se utiliza para calcular el gradiente de la función de costo.
Los parámetros del modelo se actualizan inmediatamente después de calcular el gradiente para esa única muestra.
Debido a la selección aleatoria de muestras, el proceso de actualización de parámetros es inherentemente más ruidoso y menos suave que en el descenso de gradiente tipo Batch.
SGD es más rápido en cada iteración individual y a menudo converge más rápidamente, pero puede ser más ruidoso y menos estable en términos de convergencia que el descenso de gradiente tipo Batch.
Diferencias clave:
Batch GD utiliza todo el conjunto de datos en cada iteración, lo que puede ser costoso computacionalmente, mientras que SGD utiliza una sola muestra a la vez, lo que suele ser más eficiente en términos de tiempo.
Batch GD tiene una convergencia más suave y estable debido a que utiliza gradientes promedio, mientras que SGD es más ruidoso pero a menudo converge más rápido.
Batch GD puede quedar atrapado en óptimos locales, mientras que SGD puede escapar de ellos debido a su naturaleza estocástica.
En la práctica, también existen variantes intermedias como el Mini-Batch Gradient Descent, que utiliza un pequeño conjunto de datos (mini-lote) en lugar del conjunto completo, equilibrando así los beneficios de ambas técnicas. La elección entre estas variantes depende de la naturaleza del problema y las restricciones computacionales.
[
b]AulaF_658-Gradiente_Estocastico.py
*************************************************[/b]
El descenso de gradiente estocástico (SGD por sus siglas en inglés, Stochastic Gradient Descent) es un algoritmo de optimización ampliamente utilizado en el campo del aprendizaje automático y la inteligencia artificial para entrenar modelos de machine learning, especialmente en el contexto de aprendizaje profundo (deep learning). SGD es una variante del algoritmo de descenso de gradiente clásico.
La principal diferencia entre el descenso de gradiente estocástico y el descenso de gradiente tradicional radica en cómo se actualizan los parámetros del modelo durante el proceso de entrenamiento. En el descenso de gradiente tradicional, se calcula el gradiente de la función de pérdida utilizando todo el conjunto de datos de entrenamiento en cada paso de la optimización, lo que puede ser computacionalmente costoso en conjuntos de datos grandes.
En contraste, en SGD, en cada paso de optimización se utiliza un único ejemplo de entrenamiento (o un pequeño lote de ejemplos de entrenamiento) de forma aleatoria. Esto introduce estocasticidad en el proceso, ya que el gradiente calculado en cada paso se basa en una muestra aleatoria de datos. Como resultado, el proceso de optimización es más rápido y puede converger a un mínimo local o global de la función de pérdida de manera más eficiente en muchos casos.
Los pasos generales del algoritmo de descenso de gradiente estocástico son los siguientes:
Inicializar los parámetros del modelo de manera aleatoria o utilizando algún valor inicial.
Mezclar aleatoriamente el conjunto de datos de entrenamiento.
Realizar iteraciones sobre el conjunto de datos de entrenamiento, tomando un ejemplo (o un pequeño lote) a la vez.
Calcular el gradiente de la función de pérdida con respecto a los parámetros utilizando el ejemplo seleccionado.
Actualizar los parámetros del modelo utilizando el gradiente calculado y una tasa de aprendizaje predefinida.
Repetir los pasos 3-5 durante un número fijo de iteraciones o hasta que se cumpla un criterio de convergencia.
El uso de SGD es beneficioso en situaciones donde el conjunto de datos es grande o cuando se necesita un entrenamiento rápido. Sin embargo, la estocasticidad puede hacer que el proceso sea más ruidoso y requiera una sintonización cuidadosa de hiperparámetros, como la tasa de aprendizaje. Además, existen variantes de SGD, como el Mini-Batch Gradient Descent, que toman un pequeño lote de ejemplos en lugar de uno solo, lo que ayuda a suavizar las actualizaciones de parámetros sin la necesidad de calcular el gradiente en todo el conjunto de datos.Hilario Iglesias Martínez.
******************************************************************************************
ClaseAula-F896.py
***************************************************************************************
Este ejercicio, sencillo, para aprendizaje y seguimiento de los parámetros: peso,sesgo,costo, en un descenso de gradiente tipo Batch.
***************************************************************************************
Los términos "peso", "sesgo" y "costo" pueden tener diferentes significados dependiendo del contexto en el que se utilicen. Aquí te proporcionaré una breve descripción de cada uno de estos términos en diversos contextos:
Peso (Weight):
En el contexto de la física, el peso se refiere a la fuerza gravitatoria que actúa sobre un objeto debido a la atracción de la gravedad de la Tierra. Se mide en unidades de fuerza, como newtons o libras.
En el aprendizaje automático y la inteligencia artificial, un "peso" se refiere a los coeficientes asociados con las conexiones entre neuronas en una red neuronal. Estos pesos determinan la fuerza y dirección de la influencia de una neurona en otra dentro de la red. Los pesos se ajustan durante el proceso de entrenamiento de la red para que la red pueda aprender y realizar tareas específicas.
Sesgo (Bias):
En el contexto de la estadística y el análisis de datos, el sesgo se refiere a la tendencia sistemática de un conjunto de datos o un modelo estadístico a producir resultados que se desvían de la verdad o de la población real debido a errores sistemáticos en el proceso de recopilación o modelado de datos.
En el aprendizaje automático, el sesgo (bias) es un término que se utiliza para referirse a un valor constante añadido a la salida de una función en una red neuronal. El sesgo permite que la red pueda modelar funciones más complejas, desplazando la función de activación. Es una especie de "ajuste" que ayuda a la red a aprender y generalizar mejor.
Costo (Cost):
En el ámbito empresarial y financiero, el costo se refiere a la cantidad de recursos (dinero, tiempo, esfuerzo, etc.) que se requiere para producir o realizar algo. Puede incluir costos directos e indirectos.
En matemáticas y optimización, el costo es una medida de la cantidad que se desea minimizar o maximizar en un problema. Por ejemplo, en la optimización lineal, se busca minimizar una función de costo sujeta a ciertas restricciones.
En el contexto del aprendizaje automático y la optimización de modelos, el costo es una medida de cuán bien está funcionando un modelo en relación con los datos de entrenamiento y se utiliza para ajustar los parámetros del modelo durante el proceso de entrenamiento. El objetivo es minimizar el costo para que el modelo se ajuste mejor a los datos y pueda realizar predicciones precisas en nuevos datos.
Estos son conceptos que pueden ser ampliamente aplicados en diversos campos y contextos, por lo que su significado puede variar según el contexto específico en el que se utilicen.*****************************************************************************************************
Hilario Iglesias Martínez
ClaseViernes-F543.py
DESCENSO DE GRADIENTE BATCH
*********************************************************************************************************
El "descenso de gradiente tipo Batch" es una técnica de optimización utilizada en el aprendizaje automático y la estadística para ajustar los parámetros de un modelo matemático, como una regresión lineal o una red neuronal, de manera que se minimice una función de costo específica. Es una de las variantes más simples y fundamentales del descenso de gradiente.
Aquí tienes una explicación de cómo funciona el descenso de gradiente tipo Batch:
Inicialización de parámetros: Comienza con un conjunto inicial de parámetros para tu modelo, que generalmente se eligen de manera aleatoria o se establecen en valores iniciales.
Selección de lote (Batch): En el descenso de gradiente tipo Batch, se divide el conjunto de datos de entrenamiento en lotes o subconjuntos más pequeños. Cada lote contiene un número fijo de ejemplos de entrenamiento. Por ejemplo, si tienes 1000 ejemplos de entrenamiento, puedes dividirlos en lotes de 32 ejemplos cada uno.
Cálculo del gradiente: Para cada lote, calculas el gradiente de la función de costo con respecto a los parámetros del modelo. El gradiente es una medida de cómo cambia la función de costo cuando se hacen pequeños ajustes en los parámetros. Indica la dirección en la que debes moverte para minimizar la función de costo.
Actualización de parámetros: Después de calcular el gradiente para cada lote, promedias los gradientes de todos los lotes y utilizas ese gradiente promedio para actualizar los parámetros del modelo. Esto se hace multiplicando el gradiente promedio por una tasa de aprendizaje (learning rate) y restando ese valor de los parámetros actuales. El learning rate controla el tamaño de los pasos que das en la dirección del gradiente.
Repetición: Los pasos 2-4 se repiten varias veces (llamadas épocas) a través de todo el conjunto de datos de entrenamiento. Cada época consiste en procesar todos los lotes y ajustar los parámetros del modelo.
Convergencia: El proceso de ajuste de parámetros continúa hasta que se alcanza un criterio de convergencia, que generalmente se establece en función de la precisión deseada o el número de épocas.
El descenso de gradiente tipo Batch es eficiente en términos de cómputo, ya que utiliza todos los datos de entrenamiento en cada paso de actualización de parámetros. Sin embargo, puede ser lento en conjuntos de datos grandes, y su convergencia puede ser más lenta en comparación con otras variantes del descenso de gradiente, como el descenso de gradiente estocástico (SGD) o el mini-batch SGD.
En resumen, el descenso de gradiente tipo Batch es una técnica de optimización que ajusta los parámetros de un modelo mediante el cálculo y la actualización de gradientes en lotes de datos de entrenamiento, con el objetivo de minimizar una función de costo. Es una parte fundamental en la optimización de modelos de aprendizaje automático.
*********************************************************************************************************
Ejecucion.
Bajo consola de Linux.
python3 ClaseViernes-F543.py"""
Derivada_Descenso_Gradiente.py
-----------------------------------
Que hace el programa:
Dada la parábola de esta función:
f(x,t)=(x ** 2 / 2) + t
Vamos a realizar la derivada de los puntos de una parábola
de forma inversa, lo que se define como descenso de gradiente,
a partir de un punto dado por:
init_x = 18.
Muy utilizado en Redes Neuronales.
También imprimiremos su valor al llegar
a la última vuelta del "loop" range(5000)
------------------------------------------------
Ejecución bajo consola de linux, con este comando:
python3 derivada_descenso_gradiente_1.py
-------------------------------------------------
***************************************************************
Programa Realizado Bajo plataforma Ubuntu
de linix.
Editado con Sublime text.
También se puede editar y ejecutar con Google Colab
*****************************************
"""Programa para usar ChatGPT dese la terminal. Al iniciarlo se requiere introducir la Api-Key del usuario.
PARA CUALQUIER DUDA U OBSERVACIÓN, USEN LA SECCIÓN DE COMENTARIOS.
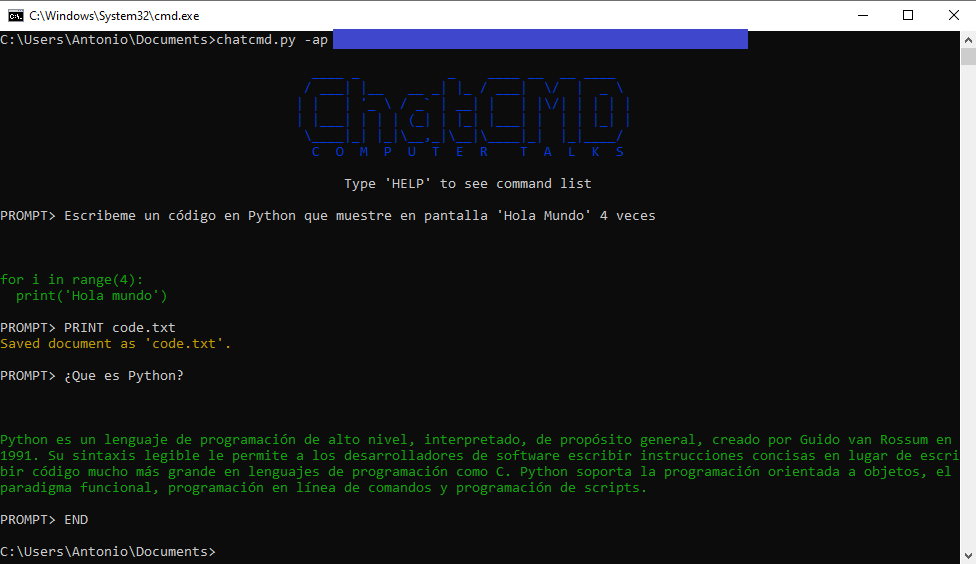
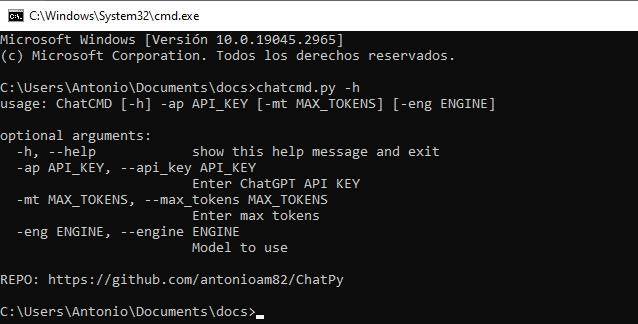
In vino veritas
////////////////////////////////////////////////////////////////////
Hilario Iglesias Martínez.
////////////////////////////////////////////////////////////////////
Archivo de clase NeuralNetwork.py
********************************
Descripción:
***********
Este archivo contiene la implementación de la clase NeuralNetwork, que representa una red neuronal básica con una capa oculta y una capa de salida. La clase está diseñada para ser utilizada en problemas de clasificación binaria, donde se tienen características de entrada y se desea predecir una salida binaria. He adoptado la predicción binaria por ser la más usual para el ejemplo.
Dentro de NeuralNetwork.py, encontrarás las siguientes partes:
Importaciones:
El archivo puede comenzar con importaciones de bibliotecas necesarias, como NumPy, para realizar operaciones matemáticas en matrices.
Definición de funciones de activación:
Es probable que encuentres las definiciones de funciones de activación como ReLU, sigmoid, y sigmoid_derivative. Estas funciones son esenciales para realizar las operaciones en las capas oculta y de salida de la red neuronal.
Definición de la clase NeuralNetwork:
Dentro de la clase NeuralNetwork, encontrarás el constructor __init__, donde se definen los atributos de la red neuronal, como el tamaño de entrada, el tamaño de la capa oculta y el tamaño de salida. También se inicializan los pesos y sesgos aleatoriamente para la capa oculta y de salida.
Métodos de la clase:
En la clase, encontrarás métodos que son esenciales para el funcionamiento de la red neuronal, como forward para propagar hacia adelante, backward para propagar hacia atrás y actualizar los pesos, train para entrenar la red neuronal con datos de entrenamiento y predict para hacer predicciones con datos de entrada nuevos.
Datos de entrenamiento y prueba:
Es posible que encuentres una sección con datos de entrenamiento y prueba, que se utiliza para entrenar y probar la red neuronal. Con ellos podrás jugar con esta red neuronal modificando parámetros y viendo los resultados.
La clase NeuralNetwork proporcionada en NeuralNetwork.py debería estar bien implementada y lista para ser utilizada en otro script, como se muestra en tu archivo neuro.py.
************************************************************************************
Archivo: neuro.py
****************
Descripción:
El archivo neuro.py es el script principal que utiliza la clase NeuralNetwork definida en el archivo NeuralNetwork.py. En este archivo, se lleva a cabo la creación de una instancia de la red neuronal, se realiza el entrenamiento y se hace una predicción con la red entrenada.
Contenido:
Importaciones:
En el archivo neuro.py, probablemente encontrarás algunas importaciones de bibliotecas necesarias para que el código funcione correctamente. Por ejemplo, es posible que encuentres una importación de NumPy para trabajar con matrices y realizar operaciones matemáticas.
Datos de entrenamiento y prueba:
El archivo contendrá una sección donde se definen los datos de entrenamiento y prueba. En el ejemplo proporcionado, los datos de entrenamiento X y y son matrices NumPy que representan características de entrada y resultados esperados (etiquetas) para una tarea de clasificación binaria.
Creación de la instancia de la red neuronal:
En este archivo, se creará una instancia de la clase NeuralNetwork definida en NeuralNetwork.py. Esto se hace mediante la creación de un objeto de la clase con los tamaños de entrada, capa oculta y capa de salida adecuados.
Entrenamiento de la red neuronal:
Una vez creada la instancia de la red neuronal, se procede a entrenarla utilizando el método train. En el ejemplo proporcionado, se entrena la red durante 10000 épocas (iteraciones) con una tasa de aprendizaje de 0.01. Durante el entrenamiento, los pesos y sesgos de la red se ajustarán para reducir la pérdida y mejorar el rendimiento de la red en la tarea de clasificación.
Predicción con la red neuronal entrenada:
Después de entrenar la red, se realiza una predicción utilizando el método predict de la red neuronal con datos de entrada nuevos o de prueba. En el ejemplo proporcionado, se hace una predicción con un conjunto de datos de entrada input_data utilizando la red neuronal previamente entrenada.
Es importante tener en cuenta que el contenido específico del archivo neuro.py puede variar según el problema que se esté abordando y cómo se haya implementado la clase NeuralNetwork en el archivo NeuralNetwork.py. Sin embargo, la estructura general debería seguir siendo similar a lo que se describió anteriormente.
*******************************************************************************
Programa realizado en una plataforma linux, en concreto Ubuntu 20.04.6 LTS.
Se ha utilizado como editor, IDE: Sublime Text.
Realizado bajo Python 3.8.10
Se entiende que los archivos: neuro.py y la clase NeuralNetwork.py deben estar
bajo el mismo directorio.
EJECUCIÓN.
-----------------
Bajo consola linux.
mismo directorio.
python3 neuro.py
El resultado que debería dar es una Predicción semejante a esta:
Predicción: [[0.50623887]]
Amare et sapere vix deo conceditur.
**********************************************************
Hilario Iglesias Martínez.
*********************************************************
Este programa realizado en lenguaje ANSI C, bajo consola en plataforma LINUX Ubuntu 20.04.6 LTS.
******************************************************************************************
Realiza el esnifado de paquetes de la red wifi, detectando previamente el dispositivo de red
y los datos básicos del paquete.
-También puedes saber tus dispositivos de red utilizando el comando bajo consola ifconfig-.
Detecta las características básicas del paquete, y reproduce por consola, la disposición
en exadecimal y en código ASCII.
----------------------------------------------------------------------------------------------------------------------------
Este programa utiliza la biblioteca libpcap para capturar paquetes de red en tiempo real.
Por lo tanto deberás tenerla instalada en el sistema.
Instala libpcap ejecutando el siguiente comando:
sudo apt install libpcap-dev
Una vez que la instalación se haya completado, puedes verificar que libpcap esté instalado correctamente ejecutando el siguiente comando:
pcap-config --version
--------------------------------------------------------
Conpilar el programa con este comando.
gcc -Werror programa.c -o programa -lpcap
Ejecutar el programa con este comando.
sudo ./programa
Como se ve hay que utilizar sudo para su ejecución
ya que es necesario tener privilegios de root
**********************************************
El código proporcionado implementa un juego de rompecabezas y acertijos diseñado para desafiar las habilidades lógicas y de resolución de problemas de los jugadores. El juego ofrece una serie de niveles con acertijos ingeniosos, laberintos complicados y rompecabezas visuales que pondrán a prueba la destreza mental de los jugadores.
La aplicación móvil ofrece una interfaz interactiva y atractiva donde los jugadores pueden explorar diferentes desafíos y avanzar en el juego. A medida que progresan, los desafíos se vuelven más difíciles, lo que mantiene el interés y la motivación de los jugadores.
El código proporciona una base sólida para la implementación del juego, incluyendo la lógica de los niveles, el manejo de los acertijos y la interacción con el jugador. También se pueden agregar funcionalidades adicionales, como sistemas de puntuación, pistas o recompensas para enriquecer la experiencia de juego.
Con este juego de rompecabezas y acertijos, los jugadores podrán poner a prueba su agudeza mental, mejorar sus habilidades de resolución de problemas y disfrutar de un desafío entretenido y estimulante en sus dispositivos móviles.


