Transformers
Python
Publicado el 23 de Octubre del 2024 por Hilario (144 códigos)
403 visualizaciones desde el 23 de Octubre del 2024
-+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Ejercicio:
<<<<<<<<<
Aula_28_Redaccion_IA.py
----------------------
Avanzando más en el tratamiento de textos, dentro de la Inteligencia Artificial. Proponemos ahora este ejercicio sencillo en el que vamos a utilizar un módulo ya entrenado en la elaboración de textos congruentes.
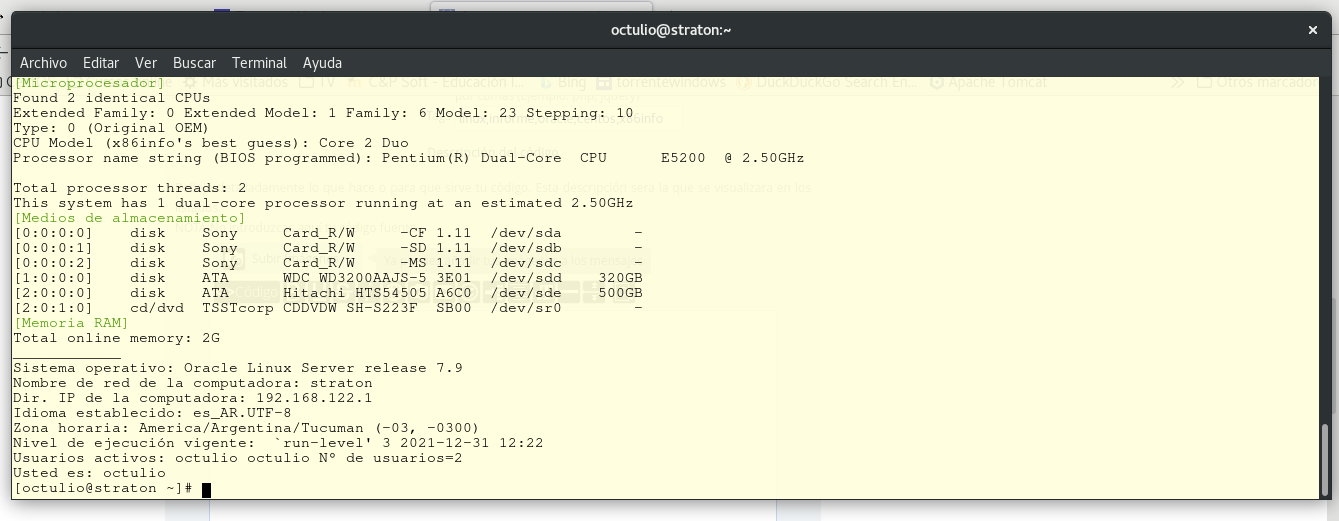
Como siempre trabajaremos bajo consola de Linux, con un sistema operativo Ubuntu 20.04.6 LTS. Utilizando como editor Sublime text.
Bien, queridos, alumnos. Para crear un programa que redacte textos amplios sobre un tema introducido por consola, puedemos usar modelos de lenguaje preentrenados, como los de la biblioteca transformers de Hugging.
Estos modelos son capaces de generar textos de manera coherente sobre prácticamente
cualquier tema. Es importante que el tema introducido por consola, sea descriptivo en el tema planteado, para que nuestro Módulo tenga más posibilidades de concretar la pequeña redacción resultante. En nuestro caso hemos planteado el tema de la siguiente forma:
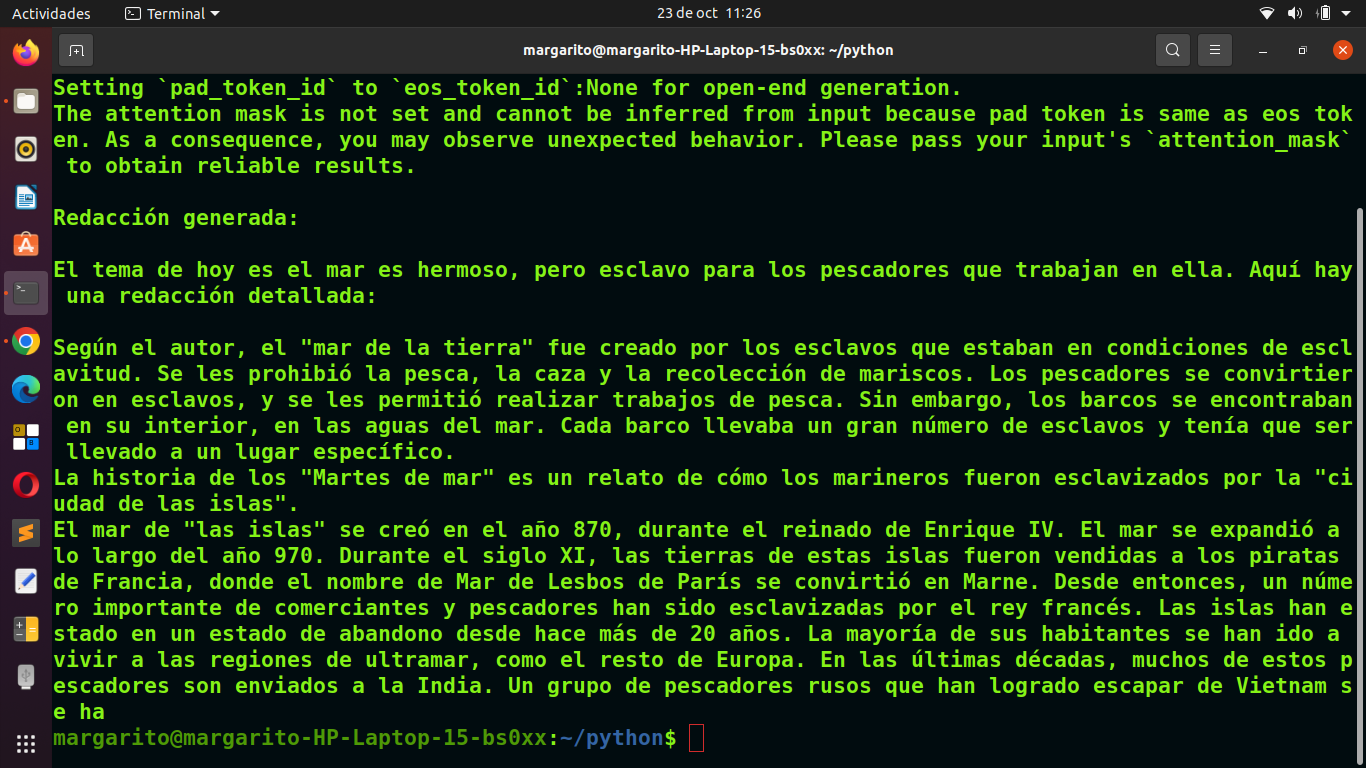
"El mar es hermoso, pero esclavo para los pescadores que trabajan en ella"
Primero, asegúrate de tener instalada la biblioteca transformers y torch si aún no las tienes.
Puedes instalarlas ejecutando en la terminal:
pip install transformers torch
***************************************************************************************
Vamos a explicar de forma breve, en que consiste y como importamos el módulo entrenado.
----------------------------------------------------------------------------------------
Módulos Importados:
GPT2LMHeadModel:
Este es un modelo preentrenado basado en GPT-2, un tipo de modelo de lenguaje desarrollado por OpenAI que genera texto. La parte LMHead se refiere a la cabeza del modelo, que está diseñada específicamente para tareas de generación de lenguaje. El modelo puede generar nuevas secuencias de texto basadas en una entrada inicial.
GPT2Tokenizer:
Este es el tokenizador de GPT-2, encargado de convertir el texto que introduces (en formato de palabras) en un formato numérico que el modelo puede entender (tokens). Cuando quieres que el modelo genere texto o lo procese, el tokenizador traduce el texto a tokens, y después de que el modelo trabaja con ellos, el tokenizador traduce esos tokens de nuevo a texto legible.
Funcionamiento:
1. Tokenización -como recordareis ya hemos explicado este tema en un ejercicio anterior-:
El texto en lenguaje natural no puede ser entendido directamente por el modelo; necesita ser convertido a un formato que pueda procesar, llamado tokens (que son números que representan palabras o partes de palabras).
Ejemplo:
Si introduces la frase "Hola mundo", el tokenizador puede convertirla en algo como [15496, 1107], donde cada número representa una palabra o fragmento de una palabra.
2. Generación del texto:
El modelo GPT-2 toma esos tokens y predice cuál debería ser el siguiente token (o secuencia de tokens) basándose en lo que ya ha "visto". Se basa en patrones que ha aprendido de grandes cantidades de datos durante su entrenamiento.
Usando el mismo ejemplo, si das el input "Hola mundo", el modelo podría generar una continuación como "es un lugar hermoso" o cualquier secuencia plausible que siga.
3. Proceso completo:
Input: Tú introduces una frase (por ejemplo, "El cielo es azul").
Tokenización: El tokenizador convierte esta frase en tokens numéricos.
Modelo GPT-2: El modelo procesa esos tokens y genera nuevos tokens que representan la continuación del texto (basado en lo que ha aprendido).
Des-tokenización: El tokenizador traduce esos nuevos tokens de vuelta a palabras legibles, generando un texto nuevo como salida.
***************************************************************************
Explicación del código:
GPT2LMHeadModel.from_pretrained('gpt2'): Carga el modelo GPT-2 preentrenado.
tokenizador.encode(): Convierte el texto de entrada en tokens.
modelo.generate(): Genera la continuación del texto basado en los tokens de entrada.
tokenizador.decode(): Convierte los tokens generados nuevamente a texto para que puedas leer la salida.
Este enfoque permite que los modelos como GPT-2 generen texto natural en una gran variedad de tareas, como responder preguntas, redactar historias o completar oraciones. Todo esto se hace aprovechando la capacidad del modelo para aprender patrones del lenguaje y generar textos coherentes basados en un contexto previo.
**************************************************************************************
La ejecucion de este programa se realiza con el siguiente comando, bajo consola de Linux:
python3 Aula_28_Redaccion_IA.py
////////////////////////////////////////////////////////////////////////////////////////////
-------------------------------------------------------------------------------------------
Como veremos en clase, el próximo 29 de Octubre, existen muchas limitaciones en este proceso.
Revisaremos el ejercicio paso a paso, y comrobaremos cómo funciona.
He de decir que partimos de una forma básica, pero intentaremos poner las bases, para aumentar la complejidad y la efectividad con nuevos ejercicios.
Nuestras limitaciones son muchas, somos meros mortales en limitaciones tecnologicas, a continuacion
os hago un resumen de nuetras limitaciones, digamos, caseras:
Cuando ejecutas módulos como GPT2LMHeadModel y GPT2Tokenizer en un ordenador normal (casero), hay algunas limitaciones que debes tener en cuenta. Aquí te detallo las más importantes:
1. Recursos de hardware:
**********************
Memoria RAM: Los modelos como GPT-2 requieren bastante memoria. Incluso el modelo GPT-2 pequeño puede ocupar varios GB de RAM. Si tu ordenador tiene poca memoria (por ejemplo, menos de 8 GB de RAM), puede que se bloquee o funcione muy lentamente, especialmente con textos largos.
GPU (Unidad de Procesamiento Gráfico): Aunque los modelos se pueden ejecutar en CPU, los modelos como GPT-2 son mucho más rápidos si se ejecutan en una GPU. Los ordenadores caseros generalmente no tienen GPUs tan potentes como las de los servidores especializados o las tarjetas gráficas usadas para IA (como las NVIDIA de la serie RTX). Sin una GPU potente, la generación de texto puede ser extremadamente lenta.
CPU: Si no tienes una GPU, el modelo se ejecutará en la CPU, pero esto hará que el procesamiento sea mucho más lento. Procesar o generar textos largos podría tomar minutos en lugar de segundos.
2. Tamaño del modelo:
********************
Versiones grandes de GPT-2: GPT-2 tiene varios tamaños (pequeño, mediano, grande y extra grande). Los modelos más grandes requieren mucha más memoria y procesamiento, lo que los hace casi impracticables en un ordenador casero promedio. Por ejemplo, el modelo más grande (GPT-2 XL) ocupa más de 6 GB solo para cargar, y esto sin contar el procesamiento del texto.
Tiempo de carga: Incluso si tu ordenador puede manejar el tamaño del modelo, cargar el modelo en la memoria puede ser lento, y cada nueva inferencia (generación de texto) puede tomar bastante tiempo.
3. Almacenamiento:
*****************
Espacio en disco: Los modelos preentrenados de GPT-2 ocupan varios gigabytes de almacenamiento. Si tienes un disco duro pequeño o poco espacio disponible, descargar y guardar estos modelos puede ser problemático.
Actualizaciones de modelos: Los modelos mejorados o adicionales también ocupan más espacio y descargar varios de ellos podría llenar el almacenamiento disponible rápidamente.
4. Rendimiento limitado en generación de texto:
**********************************************
Latencia: En un ordenador casero, puede haber una latencia significativa entre la entrada de texto y la generación de salida. Generar texto en tiempo real o manejar peticiones rápidas no es tan fluido como en infraestructuras especializadas.
Longitud del texto: La longitud del texto que puedes procesar o generar también está limitada por los recursos de tu máquina. Textos muy largos podrían hacer que el modelo consuma más memoria de la disponible, lo que puede llevar a fallos o tiempos de procesamiento extremadamente largos.
5. Optimización limitada:
************************
Uso eficiente del hardware: Los modelos como GPT-2 están optimizados para funcionar mejor en infraestructuras de alto rendimiento, donde los recursos se pueden gestionar de manera más eficiente. En un ordenador casero, la falta de optimizaciones específicas para tu hardware (como las que se usan en servidores o clusters) hará que el rendimiento sea más bajo.
6. Entrenamiento o ajuste fino (fine-tuning):
********************************************
Imposibilidad de reentrenar: Entrenar o ajustar finamente un modelo como GPT-2 en un ordenador casero es prácticamente inviable debido a la cantidad de recursos que consume. Necesitarías GPUs especializadas y días o semanas de procesamiento para reentrenar el modelo, algo que no es posible en un equipo casero normal.
Acceso a grandes datasets: Para ajustar finamente el modelo, necesitarías un conjunto de datos extenso y adecuado, lo que no siempre es fácil de gestionar ni de almacenar en un ordenador personal.
7. Conexión a internet (si usas modelos en la nube):
***************************************************
Como recurso, os digo:
Aunque puedes ejecutar los modelos localmente, algunos prefieren usar versiones en la nube o APIs (como OpenAI GPT-3) para ahorrar recursos en el ordenador local. En estos casos, dependes de una conexión a internet rápida y estable para obtener resultados eficientes. Las conexiones lentas podrían hacer que el proceso sea menos fluido.
Como os comento, los de nuestra Aula, somos puramente terrenales.
Gracias, amigos, y a trabajar.
----------------------------------------------------------------------------------------------------------