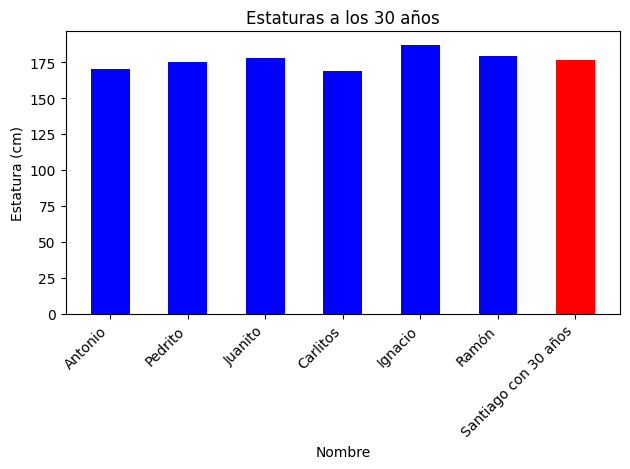
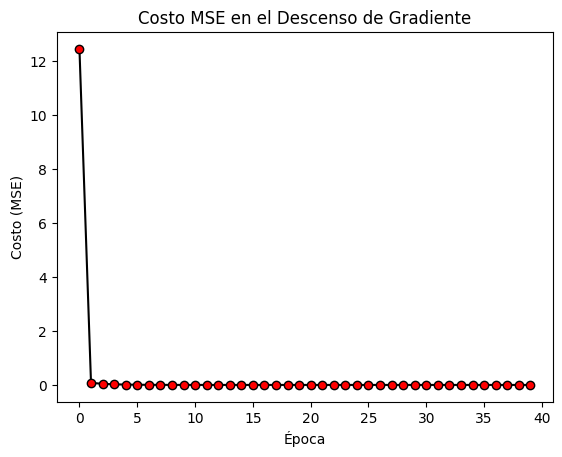
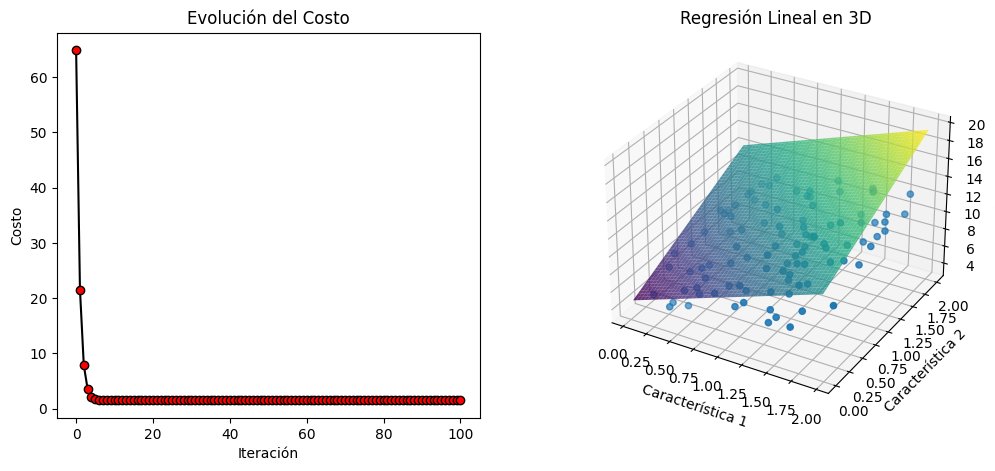
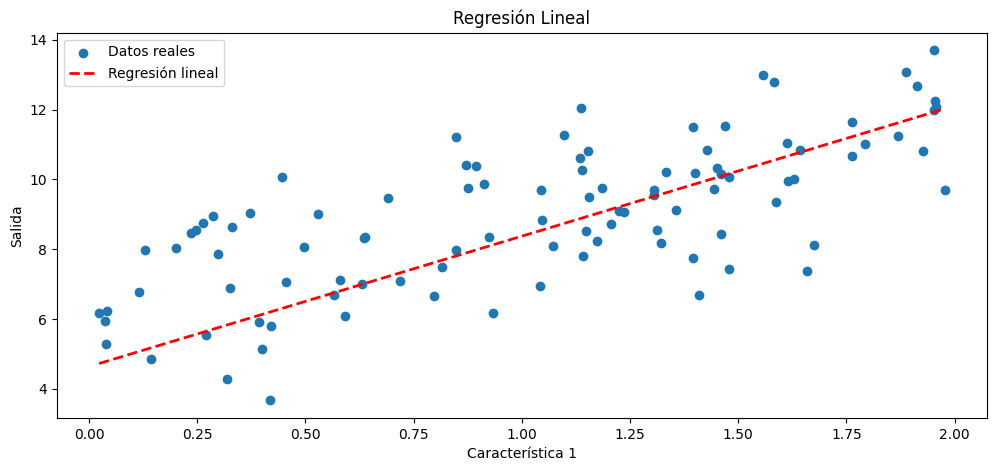
Capa convolucional.
Python
Publicado el 12 de Diciembre del 2023 por Hilario (144 códigos)
379 visualizaciones desde el 12 de Diciembre del 2023
#Aula_28_Convolucion.py
#Ejecutar:
python3 Aula_28_Convolucion.py
Propongo un sencillo ejercicio, sobre el funcionamiento de una capa convolucional (CNN).
Partimos de una imagen, y realizamos una simple convolucion, para apreciar su funcionamiento.
Para hacer más intuitivo el programa le mandamos imprimir los valores de los pixel de la imagen original, con los indices correspondientes.
A continuación describimos esquemáticamente que es una convolución.
La convolución es una operación matemática que combina dos conjuntos de datos para producir un tercer conjunto
Básicamente la convolución en una red neuronal convolucional (CNN) es una operación matemática que se utiliza para procesar imágenes y extraer características importantes. Es esencialmente una forma de explorar la imagen para buscar patrones locales. Aquí hay una explicación simple:
Imagen de Entrada, (en nuestro caso 1.jpeg):
La imagen de entrada es una matriz bidimensional de píxeles, donde cada píxel tiene un valor que representa la intensidad del color en ese punto.
Filtro o Kernel:
La convolución utiliza un filtro (también llamado kernel), que es una pequeña matriz de números.
Este filtro se desliza a lo largo de la imagen original, multiplicando sus valores con los valores correspondientes de la región de la imagen donde se encuentra.
Operación de Convolución:
Para cada posición del filtro, los valores se multiplican y suman para producir un solo valor en la nueva imagen, llamada mapa de características.
Este proceso se repite para cada posición del filtro, generando así todo el mapa de características.
Mapa de Características:
El resultado de la convolución es un mapa de características, que resalta patrones específicos aprendidos por el filtro.
Los primeros filtros en una red suelen capturar detalles simples como bordes, y a medida que avanzas en las capas, los filtros tienden a aprender patrones más complejos y abstractos.
Capas Convolucionales:
Las CNN suelen tener múltiples capas convolucionales apiladas, donde cada capa utiliza varios filtros para aprender diferentes características de la imagen.
La salida de una capa convolucional se utiliza como entrada para la siguiente, permitiendo que la red aprenda representaciones jerárquicas de las características.
En resumen, la convolución en una red convolucional es un proceso clave para detectar y resaltar patrones en una imagen. Es una técnica poderosa para el procesamiento de imágenes y ha demostrado ser muy exitosa en tareas como reconocimiento de objetos, clasificación de imágenes y segmentación de imágenes.


#Ejecutar:
python3 Aula_28_Convolucion.py
Propongo un sencillo ejercicio, sobre el funcionamiento de una capa convolucional (CNN).
Partimos de una imagen, y realizamos una simple convolucion, para apreciar su funcionamiento.
Para hacer más intuitivo el programa le mandamos imprimir los valores de los pixel de la imagen original, con los indices correspondientes.
A continuación describimos esquemáticamente que es una convolución.
La convolución es una operación matemática que combina dos conjuntos de datos para producir un tercer conjunto
Básicamente la convolución en una red neuronal convolucional (CNN) es una operación matemática que se utiliza para procesar imágenes y extraer características importantes. Es esencialmente una forma de explorar la imagen para buscar patrones locales. Aquí hay una explicación simple:
Imagen de Entrada, (en nuestro caso 1.jpeg):
La imagen de entrada es una matriz bidimensional de píxeles, donde cada píxel tiene un valor que representa la intensidad del color en ese punto.
Filtro o Kernel:
La convolución utiliza un filtro (también llamado kernel), que es una pequeña matriz de números.
Este filtro se desliza a lo largo de la imagen original, multiplicando sus valores con los valores correspondientes de la región de la imagen donde se encuentra.
Operación de Convolución:
Para cada posición del filtro, los valores se multiplican y suman para producir un solo valor en la nueva imagen, llamada mapa de características.
Este proceso se repite para cada posición del filtro, generando así todo el mapa de características.
Mapa de Características:
El resultado de la convolución es un mapa de características, que resalta patrones específicos aprendidos por el filtro.
Los primeros filtros en una red suelen capturar detalles simples como bordes, y a medida que avanzas en las capas, los filtros tienden a aprender patrones más complejos y abstractos.
Capas Convolucionales:
Las CNN suelen tener múltiples capas convolucionales apiladas, donde cada capa utiliza varios filtros para aprender diferentes características de la imagen.
La salida de una capa convolucional se utiliza como entrada para la siguiente, permitiendo que la red aprenda representaciones jerárquicas de las características.
En resumen, la convolución en una red convolucional es un proceso clave para detectar y resaltar patrones en una imagen. Es una técnica poderosa para el procesamiento de imágenes y ha demostrado ser muy exitosa en tareas como reconocimiento de objetos, clasificación de imágenes y segmentación de imágenes.